The RAG pipeline
The basic idea behind Retrieval Augmented Generation is simple. When you converse with
an AI chatbot and ask a question, the AI chatbot consults a library of documents,
retrieving the most relevant results. It then uses the content of these documents
as it generates its answer.
What makes RAG particularly powerful is that the relevant documents are not selected
by some naive algorithm such as a simple keyword search. Rather, they are classified
in advance using an AI language model, and they are organized in a semantic database
that representatively encodes the meaning and content. A popular representation is
called FAISS, or Facebook AI Similarity Search: As the name implies, the method and
corresponding software libraries were provided by Meta, the parent company of Facebook.
The reference implementation
shown here
is based on the over 11,000 mostly physics-themed answers I provided on the Quora question-and-answer
Web site.
This implementation was constructed by first storing all answers in a conventional
relational database. Next, a FAISS-compatible software library was used to create
a semantic representation. This representation is exposed as an internal microservice
for use by other components of our RAG implementation.
When the user enters a query, the query text is used to interrogate the FAISS
microservice, which returns a set of hits in the form of database record references.
The corresponding documents are then pulled from the database.
A special feature of our implementation is that the documents are not used as raw text.
Rather, they are rendered and turned into PNG graphic page images. This ensures that
in addition to the document text, their layout, diagrammatic content, and rendered
mathematical expressions are faithfully preserved. (This option is relevant in the
current context; for other applications, delivering the plain text may be preferable.)
The document images are then attached to the user's original query, for processing
by a locally run, on-premises text+vision AI model, specifically Google's
Gemma: version 3 in particular, with approximately 12 billion model parameters at
4-bit quantization. A model this size is small enough to run efficiently on
consumer-grade hardware, yet large enough to offer coherent responses even to complex
queries. In our case, Gemma is run on an NVidia 5060 Ti GPU, with 16 gigabytes of
on-card VRAM. This step completes the pipeline: the result, along with links to the
referenced documents, is presented to the user.
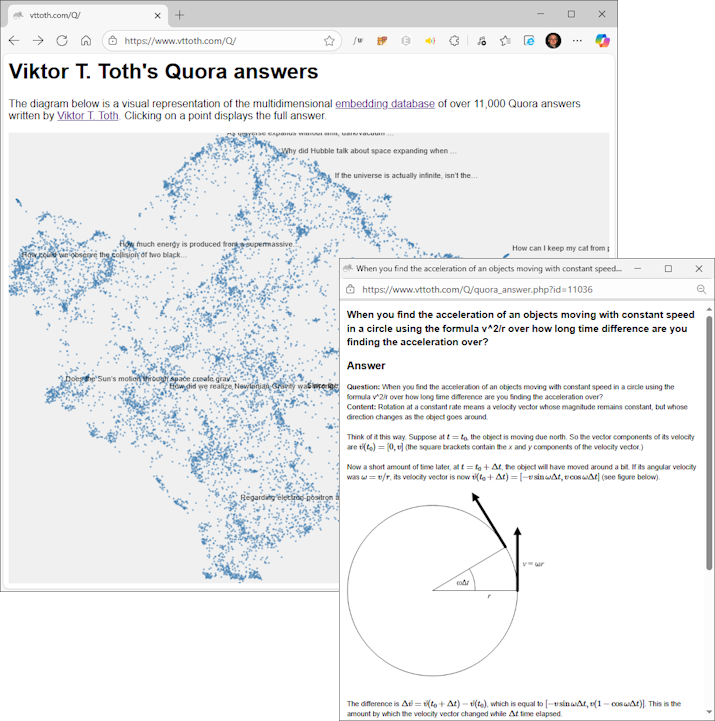
The information stored in the semantic (FAISS) database can also be visualized.
A particularly powerful visualization method is called UMAP (Uniform Manifold
Approximation and Projection): an efficient, effective method to "project" the
abstract, high-dimensional mathematical space that is the FAISS semantic representation
into a two-dimensional "cloud" of projections. Our implementation also includes just
such a projection,
in the form of an interactive visualization, with clickable points and popups that
contain the documents in question.
The reference implementation demonstrated here is "production ready" and deployable.
Multimodal chatbot... »